
If You Cannot Audit AI Hiring, Do Not Scale It
Build trust. Add accountability. Scale with confidence.

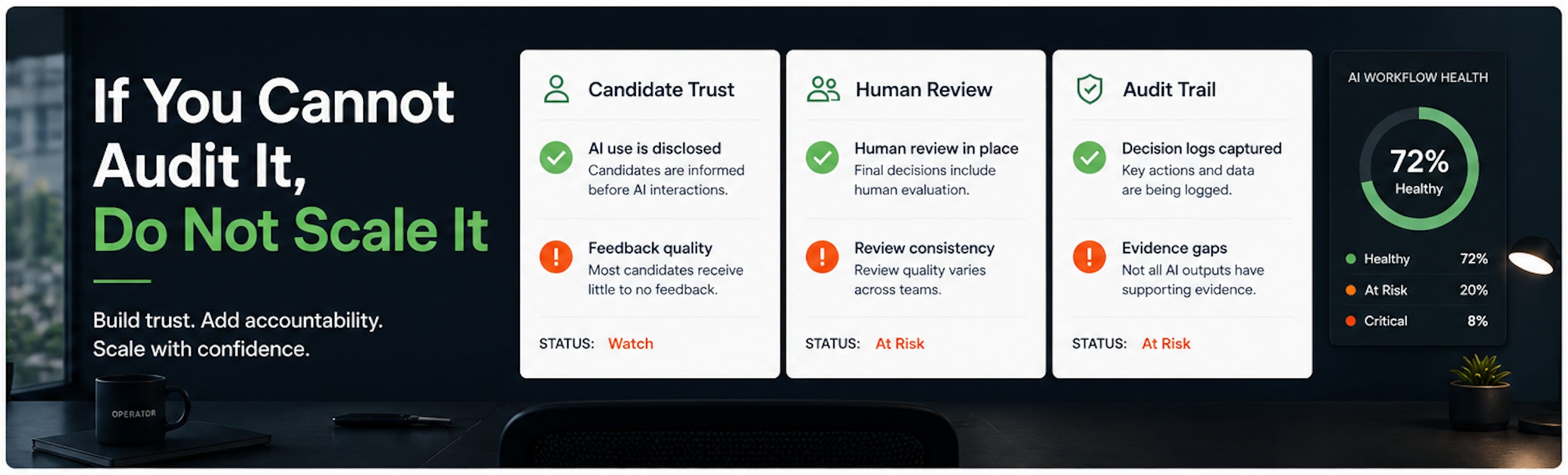
Most recruiting teams are focused on adding AI.
That is the wrong focus.
The real issue is trust.
AI is already changing candidate experience faster than teams are explaining, governing, or reviewing it.
That gap creates risk.
Not because AI is bad - but because it changes accountability.
If you cannot explain your hiring process to a candidate, a hiring manager, and legal without improvising, you are not ready to scale AI.
Here’s the short version before we go deeper:
2-Minute Skim
Three things to know:
Candidates are not rejecting AI outright. They are rejecting undisclosed, impersonal, no-feedback AI interviews.
AI hiring tools still fail without structured criteria, traceable evidence, and a named human decision owner.
Agent management is becoming real operating work: owners, KPIs, review cadences, checkpoints, and escalation rules.
Two things to test:
Run a 45-minute AI-interview trust audit on one live funnel: disclosure, criteria, human review, opt-out path, and follow-up SLA.
Create a performance scorecard for one recruiting AI workflow: accuracy, tone, escalation quality, time saved, and exception rate.
One thing to ignore:
The idea that better models will fix weak hiring processes. They will make weak processes faster, harder to explain, and more visible to candidates.
Executive Brief
What changed this week: AI moved deeper into hiring decisions. Guardrails are trying to catch up. Greenhouse published direct candidate data showing how quickly AI interviews have become common and how badly transparency is lagging. Salesforce gave a useful operating model for managing agents like digital workers, not magic prompts. LangChain mapped EU AI Act requirements to agent logs, evaluations, human intervention, and post-market monitoring. OpenAI added stronger account security and opened a more enterprise-friendly AWS path for models and managed agents.
What most teams will get wrong: they will expand AI hiring tools before defining what AI is allowed to influence and before making that clear to candidates. That is backwards. The operational risk is not that AI is too slow. The risk is that nobody can explain what it did, why it mattered, or who owned the final decision.
What to do instead: pick one high-volume workflow, define the decision standard, expose AI use clearly to candidates, keep a human review point, and measure agent performance weekly. If you cannot audit it, do not scale it.
What Matters Most This Week
1. Candidates want AI transparency
Greenhouse surveyed 2,950 job seekers and found 63% of US candidates have experienced an AI interview, but 70% were not clearly told AI was involved before the interview. 38% have already withdrawn from a process because it included an AI interview.
Recruiting use case: Audit every AI interview touchpoint for disclosure, evaluation criteria, human review, opt-out path, and follow-up communication.
Takeaway: AI interviews are not ready to run quietly in the background. Treat disclosure as candidate experience infrastructure.
Operator POV: If candidates discover AI only after they are already in the process, you are not being innovative. You are training candidates not to trust you.
Source: Greenhouse, Apr 30, 2026. Credibility: primary recruiting-tech source with a multi-country candidate survey; vendor-positioned but directly relevant and data-backed.
2. AI hiring tools still need structured hiring underneath
Greenhouse argues that AI reflects the hiring system it is applied to. Without defined competencies, scorecards, evidence standards, and decision ownership, AI creates a black-box version of your existing inconsistency.
Recruiting use case: Before enabling AI screening or matching, require a role-level scorecard with observable evidence for each must-have criterion.
Takeaway: Do not let AI evaluate anything your hiring team has not already defined.
Operator POV: AI-powered screening without a structured scorecard is just faster vibes with a legal invoice attached.
Source: Greenhouse, Apr 30, 2026. Credibility: primary source from a recruiting platform ML/product leader; practical but aligned to Greenhouse’s product worldview.
3. AI agents need performance reviews
Salesforce profiled companies managing agents with job descriptions, KPIs, quality checkpoints, weekly reviews, and human coaching. The shift is treating agents as managed work systems, not one-off automations.
Recruiting use case: Create a weekly QA review for any agent drafting outreach, triaging applicants, answering employee questions, or preparing interview packets.
Takeaway: Assign every recruiting agent an owner, success metrics, failure examples, and escalation rules.
Operator POV: If no one owns agent quality, the agent owns your candidate experience. That is not acceptable.
Source: Salesforce, Apr 29, 2026. Credibility: high-signal operator story with solid practices and vendor framing; verify ROI claims internally before repeating them.
4. EU AI Act readiness is becoming operational
LangChain mapped high-risk AI requirements to trace logs, evaluators, human-in-the-loop controls, bias monitoring, data residency, and incident processes. Recruitment is explicitly in scope for high-risk AI systems.
Recruiting use case: Use the mapping as a checklist for AI screening, ranking, matching, or interview systems touching EU candidates.
Takeaway: Start with logs, evaluation samples, human override, and post-launch monitoring. Policy language alone is not enough.
Operator POV: If your vendor cannot show traceability, human intervention, and monitoring, they are asking you to carry their regulatory risk.
Source: LangChain, Apr 27, 2026. Credibility: technical vendor source with clear article-to-capability mapping; not legal advice, but operationally useful.
5. ChatGPT account security matters for recruiting operations
OpenAI introduced Advanced Account Security with phishing-resistant sign-in, stronger recovery, shorter sessions, session visibility, and automatic training exclusion. Recruiters are putting sensitive candidate and strategy context into AI tools.
Recruiting use case: Require stronger authentication and session review for anyone using AI tools with candidate notes, compensation context, offer strategy, or employee data.
Takeaway: Treat AI accounts like systems of record, not casual browser tools.
Operator POV: The easiest AI breach will be a recruiter account with sensitive prompts and weak login controls.
Source: OpenAI, Apr 30, 2026. Credibility: primary security announcement; opt-in consumer/pro account feature today, enterprise implications are clear.
6. OpenAI on AWS lowers enterprise friction for governed agents
OpenAI models, Codex, and Bedrock Managed Agents are coming to AWS in limited preview, giving enterprises a path to deploy OpenAI capabilities inside existing AWS security, billing, procurement, and compliance workflows.
Recruiting use case: If your company standardizes on AWS, ask internal AI/platform teams whether recruiting use cases can inherit approved Bedrock governance instead of buying isolated point tools.
Takeaway: Enterprise AI buying will move toward approved infrastructure paths. TA should align with that rather than creating shadow AI stacks.
Operator POV: This is not a reason for TA to build agents. It is a reason to stop evaluating AI vendors without IT, security, and data governance in the room.
Source: OpenAI, Apr 28, 2026. Credibility: primary product announcement; limited preview, so practical availability will vary.
7. Document agents are getting more practical for recruiting ops
LlamaIndex refactored LlamaParse MCP around Parse, Classify, and Split tools with OAuth, file upload flows, observability, and rate limiting. Recruiting is full of messy documents: resumes, portfolios, interview notes, role briefs, offer docs, policy PDFs, and agency submissions.
Recruiting use case: Test document parsing on one narrow workflow, such as extracting structured evidence from intake notes and resumes into a scorecard draft.
Takeaway: Document AI is useful when it produces reviewable evidence, not when it pretends to make hiring decisions.
Operator POV: Use document agents to reduce admin drag. Do not use them as a proxy for candidate judgment.
Source: LlamaIndex, Apr 29, 2026. Credibility: primary technical source with implementation detail; requires technical setup or vendor support.
Playbook: AI Interview Trust Audit
Most teams skip this step. That is why AI hiring breaks. Use this on one active role where AI touches screening, interviewing, note-taking, scoring, or follow-up.
Goal: reduce candidate trust risk before scaling AI deeper into the funnel.
Tools:
ATS stage map
Candidate emails and prep materials
AI vendor workflow screenshots or documentation
Scorecard or interview rubric
Spreadsheet or doc for audit notes
Legal/compliance partner if AI influences evaluation
Setup:
Pick one role with current candidate traffic.
List every place AI is used or may influence candidate evaluation.
Pull 5 recent candidate journeys from application to current stage.
Identify the human decision owner for each AI-supported step.
Workflow:
Map the candidate-facing AI moments: application screen, chatbot, recorded interview, AI interviewer, note-taking, score summary, ranking, rejection email, scheduling, or follow-up.
Check disclosure: does the candidate know AI is involved before the step starts?
Check clarity: does the candidate know what AI is evaluating or supporting?
Check human review: is there a person reviewing AI output before decisions?
Check opt-out or accommodation path: can a candidate request a human alternative or support?
Check evidence quality: does the AI output cite observable candidate evidence, or does it make unsupported judgments?
Check follow-up SLA: does every candidate who completes an AI interview receive a clear outcome or next step?
Log gaps as Red, Yellow, or Green.
Fix the highest-risk gap before expanding AI usage.
Prompt to use after removing sensitive candidate identifiers:
You are auditing an AI-supported recruiting workflow for candidate trust, explainability, and operational risk.
Identify:
1. Where candidates may not understand AI is being used
2. Where evaluation criteria are unclear
3. Where human review is missing or weak
4. Where candidate follow-up could fail
5. The top 3 fixes before scaling
Be direct. Do not suggest policy unless it changes candidate experience.
Workflow:
[paste sanitized workflow]
Candidate communications:
[paste sanitized emails/prep text]
Scorecard criteria:
[paste criteria]
Common mistakes:
Saying “AI is used” without explaining where or why.
Letting AI score candidates against vague traits like culture fit or communication quality without evidence definitions.
Assuming vendor compliance language equals candidate trust.
Measuring time saved but not candidate drop-off, complaints, or no-response rates.
Failing to tell candidates when a human reviewed the output.
When not to use this:
Do not use AI interviews for roles where communication style, accent, disability accommodation, or schedule flexibility could create avoidable bias risk without strong human review.
Do not use AI evaluation if the role lacks a structured scorecard.
Do not use AI as the sole rejection trigger for qualified candidates.
Expected outcomes:
30 to 60 minutes saved per role by finding trust gaps before they become escalations.
Lower candidate drop-off from surprise AI steps.
Better defensibility because AI output is tied to explicit criteria and human ownership.
Cleaner vendor conversations because you can ask for specific controls, not generic AI assurances.
What good looks like:
Candidates are told before AI is used.
Criteria are stated in plain language.
AI outputs cite evidence and uncertainty.
Humans own decisions.
Candidates receive timely outcomes.
The team can explain the process to a candidate, executive, or regulator without improvising.
This is the baseline. If any layer is missing, trust breaks.

Prompt Chain: Candidate Trust Review for AI-Supported Hiring
Use case: Review a role’s AI-supported hiring process and produce practical fixes before candidates experience it.
System prompt:
You are a skeptical recruiting operations advisor. Your job is to improve candidate trust, process clarity, and decision defensibility in AI-supported hiring workflows. You do not write generic AI policy. You identify concrete operational risks and fixes. Prioritize candidate experience, structured hiring, human accountability, and auditability.
User prompt 1:
Review this hiring workflow. Identify every point where AI is used, may influence a candidate outcome, or may affect candidate perception.
Return a table with: workflow step, AI involvement, candidate-visible risk, decision risk, severity, and fix.
Workflow:
[paste workflow]
User prompt 2:
Rewrite the candidate communication below so it clearly explains where AI is used, what it does, what it does not decide, and how a human is involved.
Keep it concise, plain-spoken, and confidence-building. Do not overpromise fairness or accuracy.
Current message:
[paste message]
User prompt 3:
Create a human review checklist for this AI output. The reviewer must decide whether the AI summary is accurate, evidence-based, complete, and appropriate to use.
AI output:
[paste output]
Role criteria:
[paste scorecard]
Expected outputs:
Risk table
Revised candidate disclosure
Human review checklist
Top 3 fixes before launch
How to adapt:
For high-volume roles, add candidate drop-off and follow-up SLA checks.
For EU candidates, add logging, human override, and post-market monitoring requirements.
For executive roles, add confidentiality and account-security checks.
When this breaks:
The scorecard is vague or missing.
The AI vendor will not expose how outputs are generated.
Candidate communications are controlled by another team and cannot be changed quickly.
The team wants AI to make rejection decisions without human review.
Capability Radar
Greenhouse AI interview research: Adopt the transparency checklist, but do not treat vendor content as neutral research.
Salesforce agent performance reviews: Test the management model for one recruiting agent or automation.
LangChain EU AI Act mapping: Use as an operational checklist, not legal advice.
OpenAI Advanced Account Security: Adopt for recruiters handling sensitive AI workflows.
OpenAI on AWS: Watch if your enterprise already uses AWS/Bedrock for governed AI.
LlamaParse MCP: Watch/test for document-heavy recruiting ops workflows.
Glean Waldo: Watch for enterprise search efficiency; useful pattern, not a standalone TA action this week.
Fast Wins
Add one sentence to candidate prep emails explaining where AI is used, what it supports, and who makes decisions.
Review 5 recent AI-assisted candidate summaries and mark unsupported claims in red.
Turn on stronger authentication for AI accounts used with candidate or employee data.
Create a one-page agent scorecard with owner, KPI, review cadence, escalation rule, and stop condition.
Ask your AI vendor: “Can we export logs showing inputs, outputs, human review, and override events?”
Strategic Experiments
AI Interview Trust Fix
Hypothesis: Clear disclosure plus visible human review reduces candidate drop-off without slowing the funnel.
Test: Update disclosure and follow-up for one role using AI interviews.
Measure: AI-interview completion rate, candidate withdrawals, candidate questions/complaints, time-to-next-step, offer acceptance sentiment.
Recruiting Agent Performance Review
Hypothesis: Weekly human QA improves agent output quality more than prompt tweaks alone.
Test: Pick one agent that drafts outreach or summaries and review 20 outputs weekly for 3 weeks.
Measure: factual accuracy, tone quality, edit distance, recruiter time saved, escalation rate.
Document-to-Scorecard Assistant
Hypothesis: Document parsing can reduce recruiter admin while preserving human judgment.
Test: Convert intake notes and resumes into structured scorecard drafts for one role.
Measure: minutes saved per candidate, unsupported claims, recruiter edits, hiring manager usefulness rating.
Saved for Later
Mistral Medium 3.5 and remote agents are worth watching for teams building internal tools, especially where self-hosting or non-US provider options matter.
GitHub Copilot GPT-5.5 matters for engineering assessment design, but it is not a TA operating priority unless you hire engineers at scale.
Glean Waldo is a useful architecture signal: specialized search models may reduce enterprise AI cost and latency, but most TA teams should wait for this to show up inside tools they already use.
Sources
Greenhouse, “AI interviews in hiring: What candidates actually want - and how to get it right,” Apr 30, 2026, https://www.greenhouse.com/blog/2026-candidate-ai-interview-report
Greenhouse, “Why AI in hiring tech fails without structure,” Apr 30, 2026, https://www.greenhouse.com/blog/ai-in-hiring-tech-structured-hiring-foundation
Salesforce, “Your AI Agent Needs a Performance Review. Here’s How to Give One,” Apr 29, 2026, https://www.salesforce.com/news/stories/ai-agents-need-performance-reviews/
LangChain, “How LangSmith and LangChain OSS Help You Meet EU AI Act Requirements,” Apr 27, 2026, https://blog.langchain.com/langsmith-langchain-oss-eu-ai-act/
OpenAI, “Introducing Advanced Account Security,” Apr 30, 2026, https://openai.com/index/advanced-account-security/
OpenAI, “OpenAI models, Codex, and Managed Agents come to AWS,” Apr 28, 2026, https://openai.com/index/openai-on-aws/
LlamaIndex, “LlamaParse MCP: Agentic OCR tools for your AI agents,” Apr 29, 2026, https://www.llamaindex.ai/blog/llamaparse-mcp-the-tooling-layer-for-your-document-agents
Glean, “Glean Waldo,” Apr 28, 2026, https://www.glean.com/blog/waldo-launch
Mistral AI, “Remote agents in Vibe. Powered by Mistral Medium 3.5,” Apr 29, 2026, https://mistral.ai/news/vibe-remote-agents-mistral-medium-3-5
GitHub Changelog, “GPT-5.5 is generally available for GitHub Copilot,” Apr 24, 2026, https://github.blog/changelog/2026-04-24-gpt-5-5-is-generally-available-for-github-copilot
Final Take
If your AI hiring process cannot be explained, it cannot be trusted. If it cannot be trusted, it will fail - with candidates first.
Start small.
Audit one workflow.
Fix the gaps.
Then scale.